Ensemble Learning of Text Detection for Large Language Models
Based on Integrated Language Features
1 Abstract
2 Methodology
System Architecture
Input Text
Text to be classified
Feature Extraction
BERT + Statistical Features
Weak Detectors
6 Specialized Models
Ensemble Voting
Majority Decision
Final Classification
Human vs AI-generated
BERT-based Detectors
Leverages pre-trained models' semantic understanding capabilities:
- BERT Detector: Deep semantic feature extraction
- BERTTextCNN: Combines BERT with CNN for pattern recognition
Multi-Feature Detection
Integrates multiple linguistic features:
- Token Probability: GPT-2 log-likelihood analysis
- Syntactic Structure: Dependency parsing and tree analysis
- Lexical Diversity: Type-token ratio and semantic richness
Statistical Detectors
Probabilistic analysis methods:
- Log-Probability: Token likelihood patterns
- Log-Rank: Probability rank distributions
3 Experimental Results
Performance Metrics
Accuracy
Accuracy
Reduction
Detectors
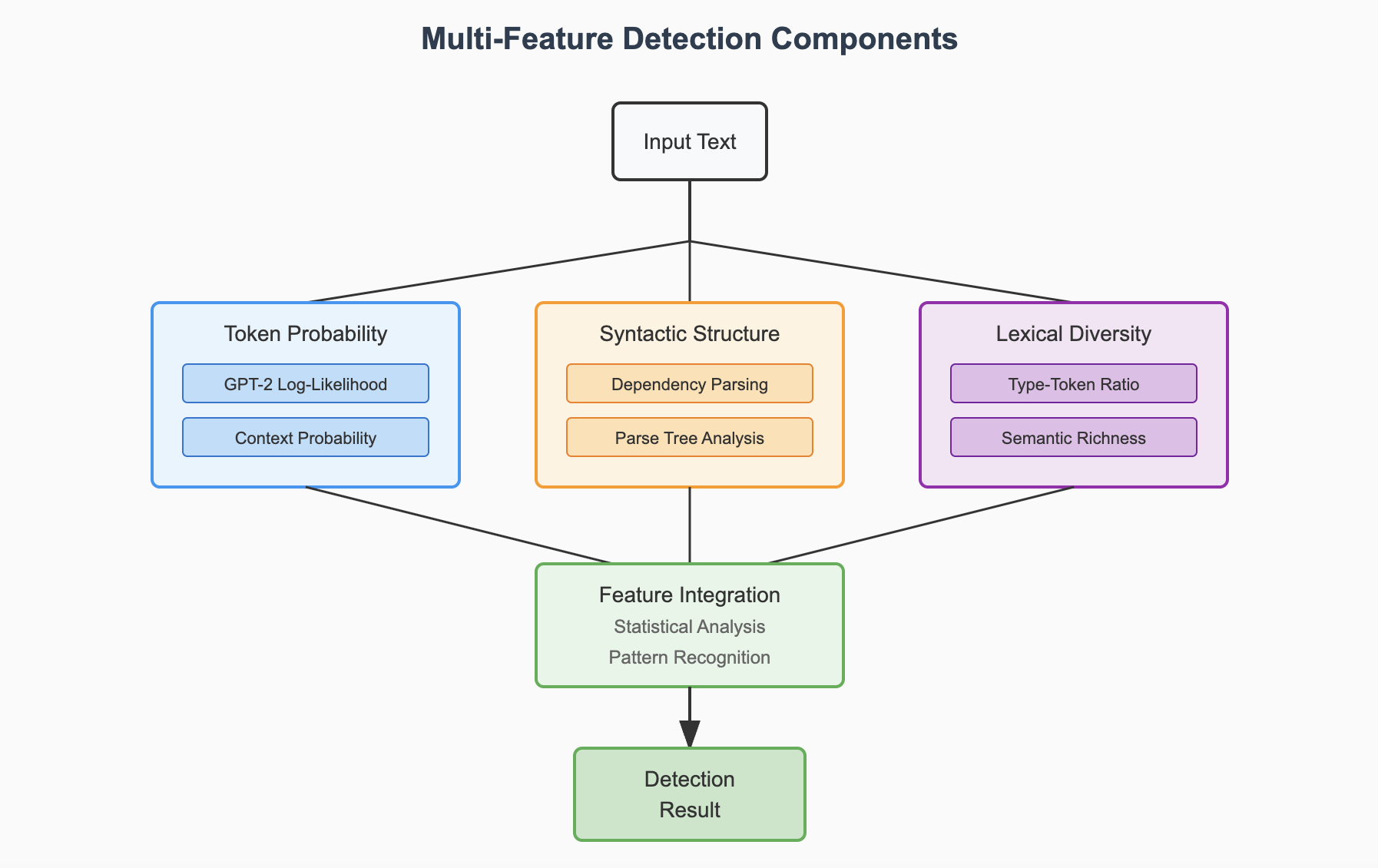
Figure 1: Detection accuracy comparison showing EBF Detection outperforming other methods with 98.55% accuracy
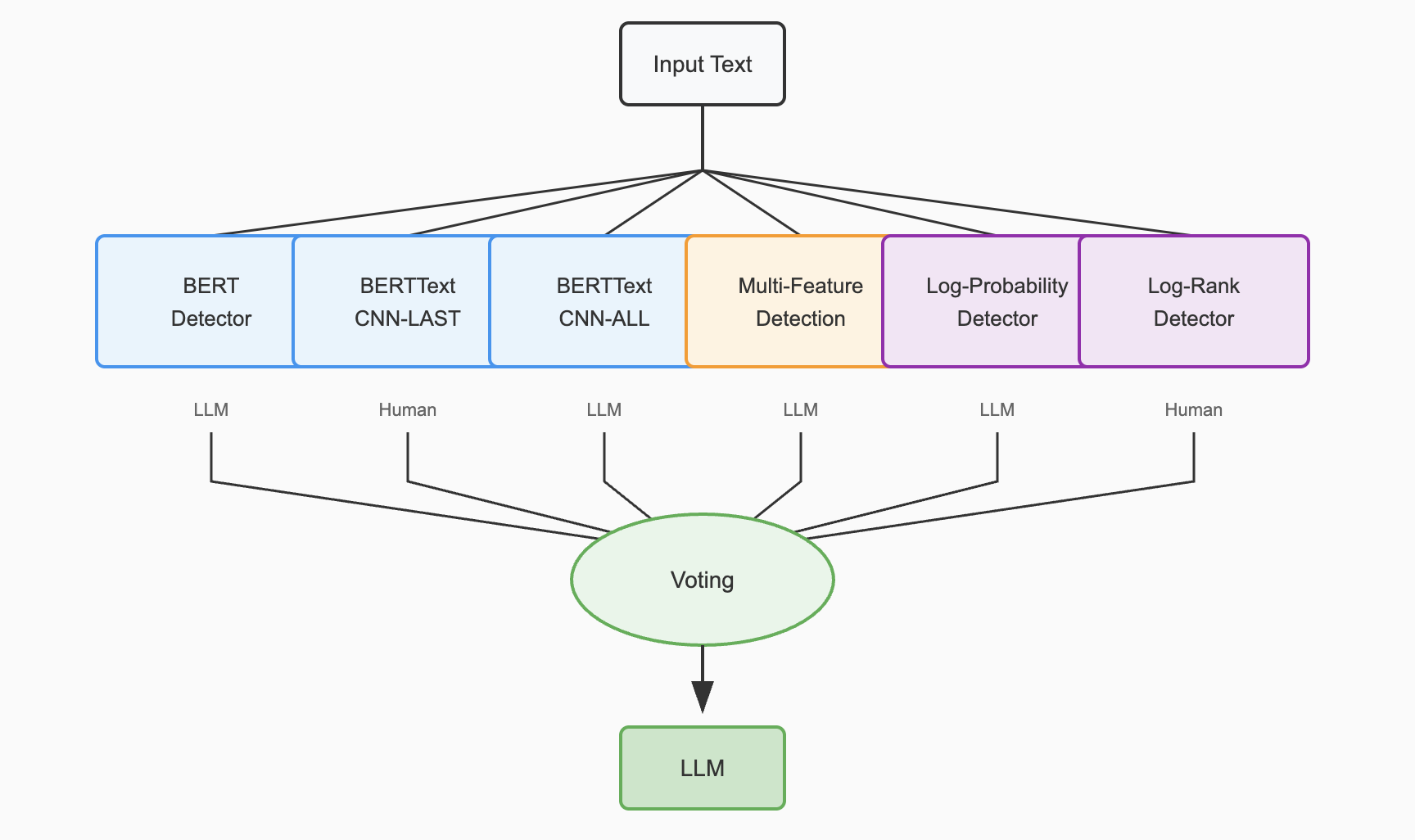
Figure 2: Multi-Feature Detection Components showing the integration of token probability, syntactic structure, and lexical diversity features
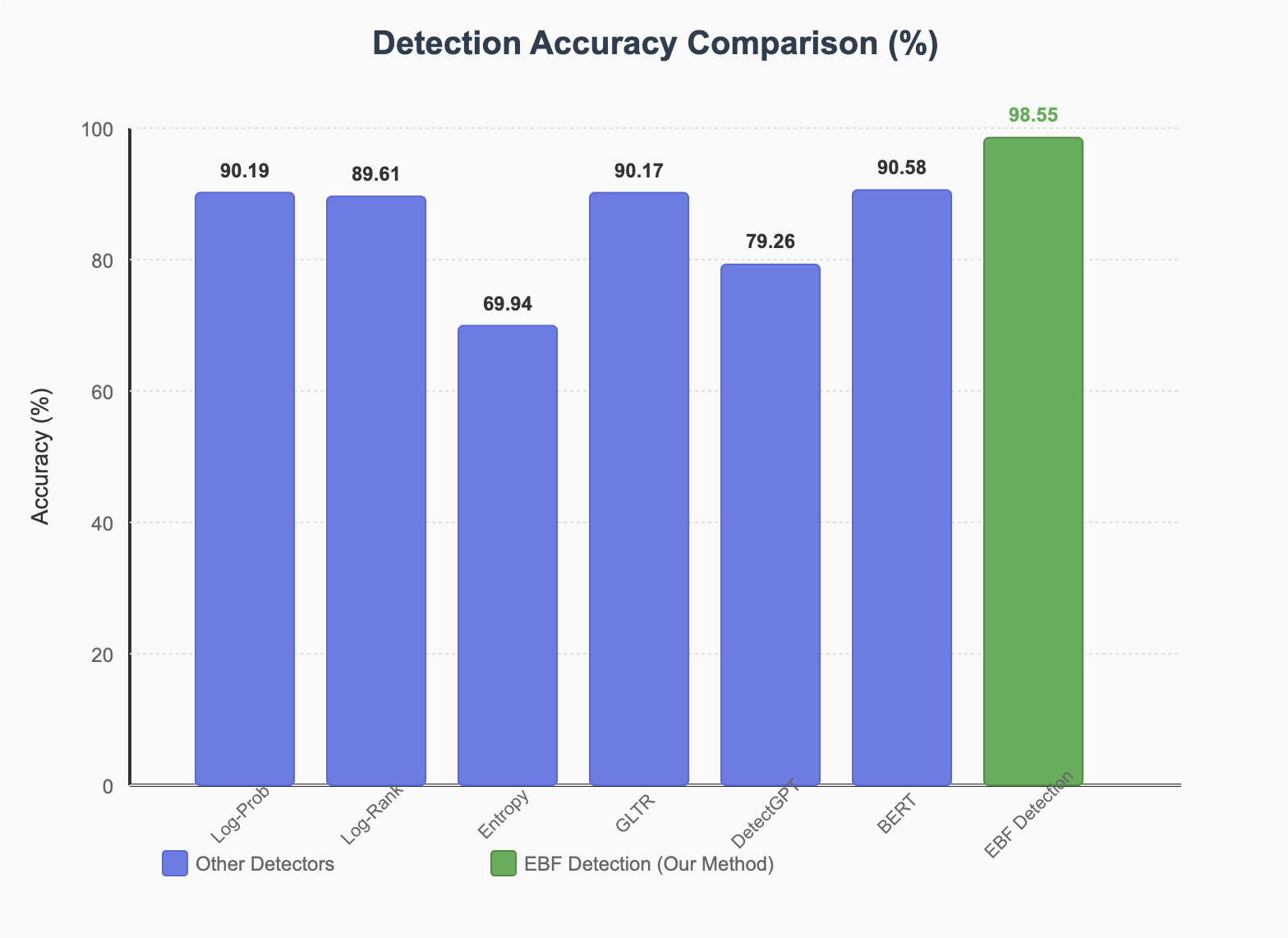
Figure 3: Radar chart comparing in-domain and out-of-domain performance across different detection methods
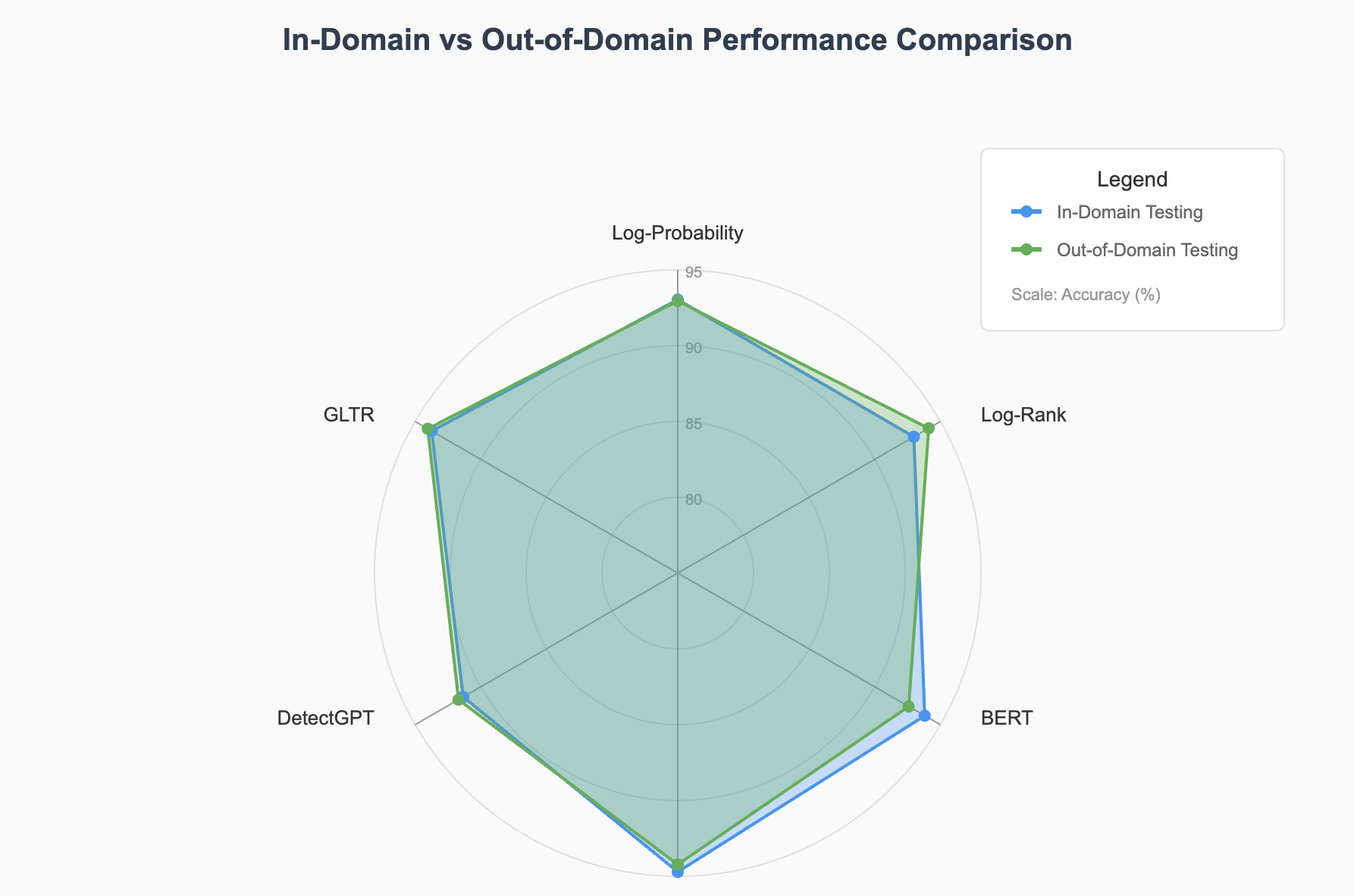
Figure 4: Overall architecture of EBF Detection showing the voting mechanism combining six detectors
| Method | In-Domain Accuracy (%) | Out-of-Domain Accuracy (%) | F1 Score |
|---|---|---|---|
| Log-Probability | 90.19 | 89.77 | 90.42 |
| Log-Rank | 89.61 | 90.40 | 90.32 |
| GLTR | 90.17 | 88.10 | 90.14 |
| DetectGPT | 79.26 | 87.52 | 79.69 |
| BERT | 90.58 | 85.66 | 90.60 |
| EBF Detection | 98.55 | 96.06 | 98.47 |
4 Key Components
BERT-based Detectors
The BERT Detector and BERTTextCNN leverage pre-trained models' semantic understanding capabilities, which are effective in capturing deep contextual differences between human and AI-generated text. These models excel at understanding semantic coherence and contextual relationships.
Statistical Feature Detectors
Multi-Feature Detection focuses on shallow linguistic statistics including:
- Token Probability: Calculated via GPT-2 log-likelihood and context probability
- Syntactic Structure: Extracted using dependency parsing and parse tree analysis
- Lexical Diversity: Quantified by type-token ratio and semantic richness metrics
Ensemble Integration
The integration process combines outputs using majority voting, leveraging the complementary strengths of deep semantic features (from BERT-based models) and shallow statistical features (from multi-feature and log-based detectors). This ensures comprehensive coverage of both semantic and stylistic differences.
5 Conclusion
This paper introduces EBF Detection, a robust method for detecting text generated by large language models. By integrating multiple weak detectors through ensemble learning, the approach achieves:
Superior Performance
Industry-leading accuracy of 98.72% on in-domain data, significantly outperforming existing methods
Excellent Generalization
Maintains 96.79% accuracy on out-of-domain data, demonstrating robustness to domain shifts
Practical Implementation
Does not require watermarking or modification of generated text, preserving naturalness
Future Work
Future research will focus on:
- Exploring new text features that can handle cases of insufficient text length
- Analyzing text features under adversarial attacks
- Extending the framework to detect text from emerging language models